Extracting ext and images from PDF Files
If you want to grab a text from a PDF file, it's fine to open the file in a PDF viewer and copy and paste the content. However, sometimes you have a longer PDF document from which you want to extract all the text and images to reuse it in some way. Blogely can help you do that by parsing the PDF from the document into your article or research document.
All you need to do is import a PDF file into your article or research doc.
Import PDF as the article:
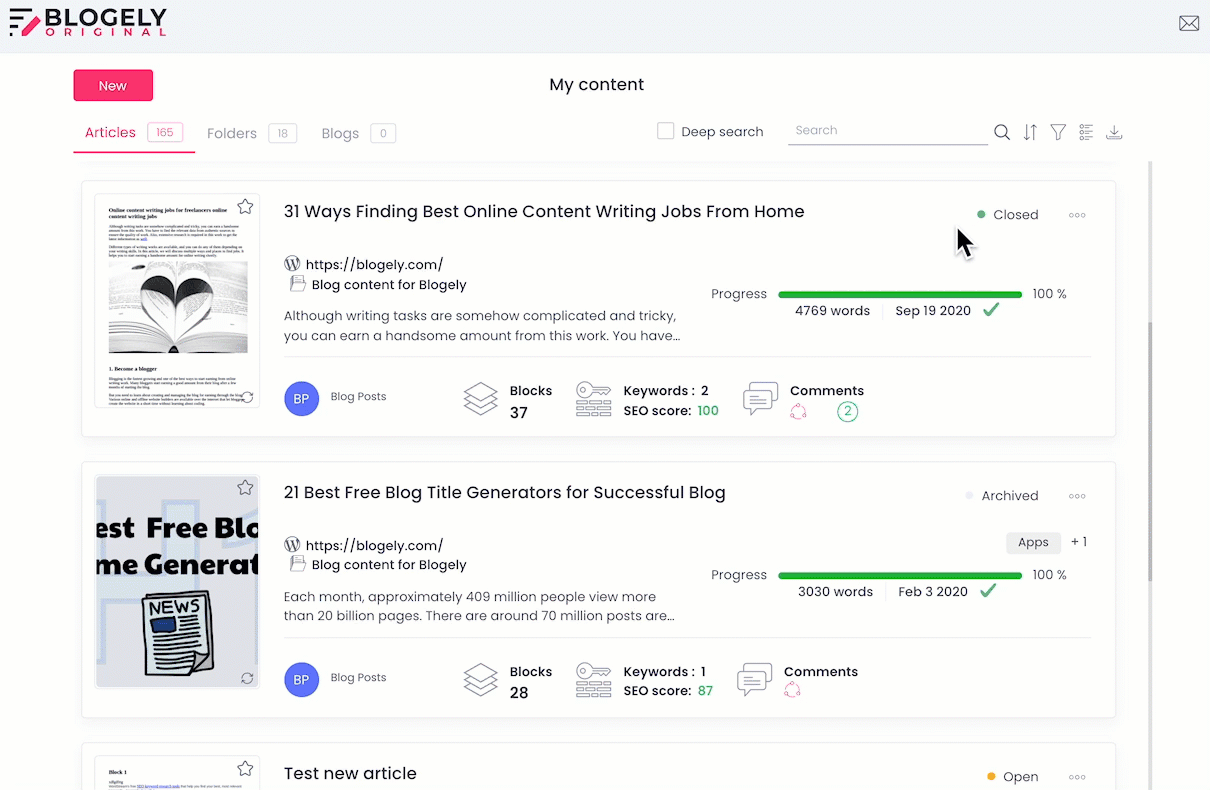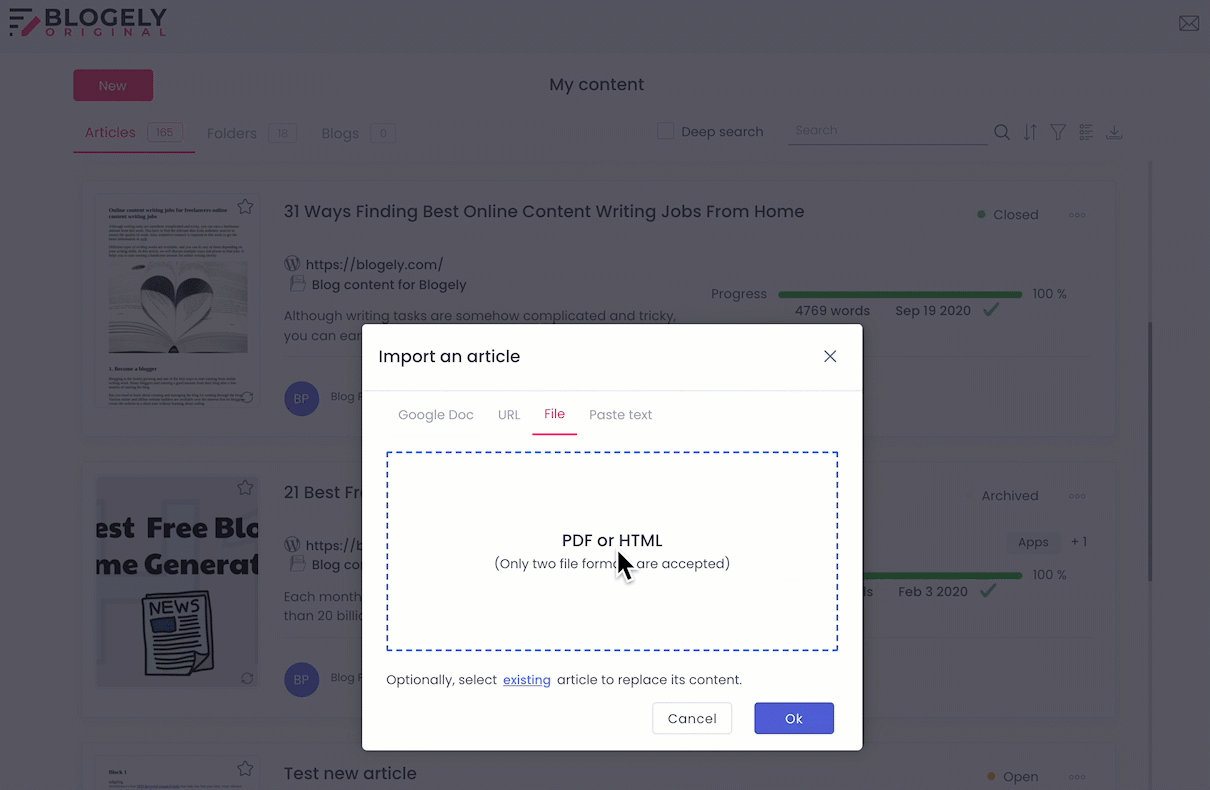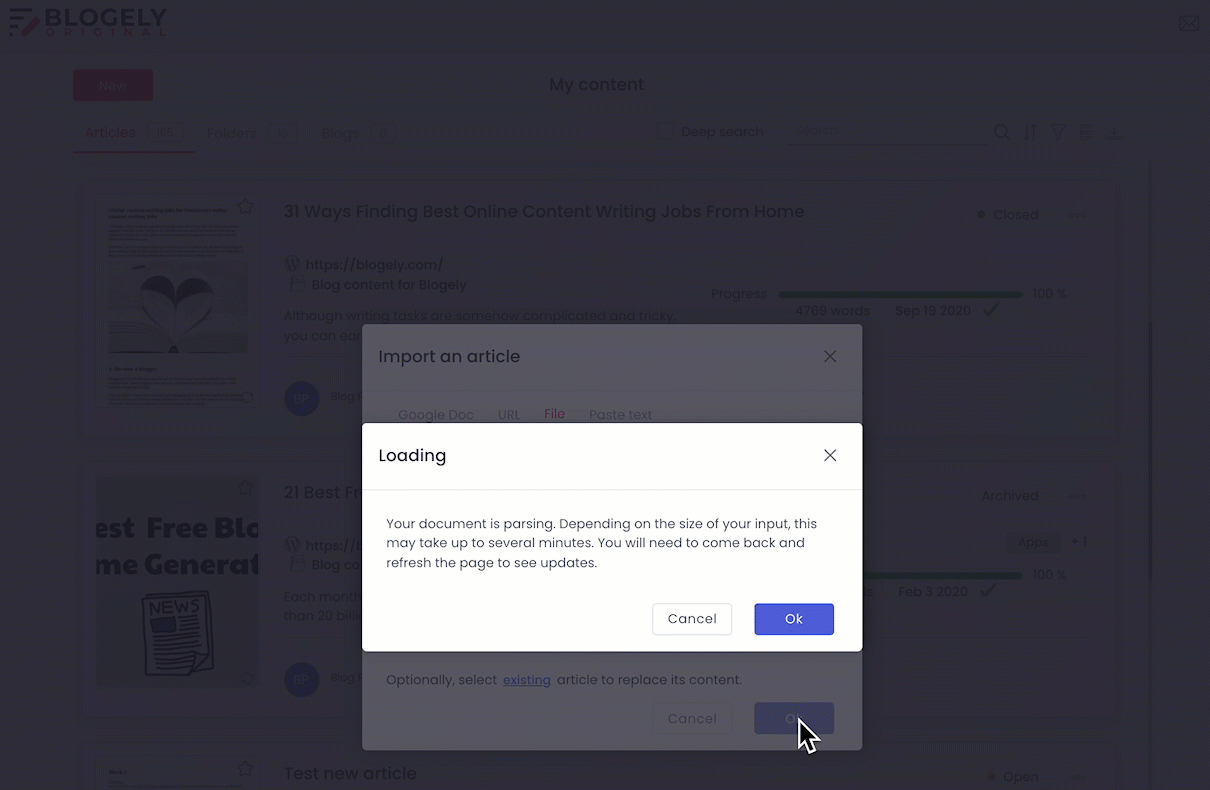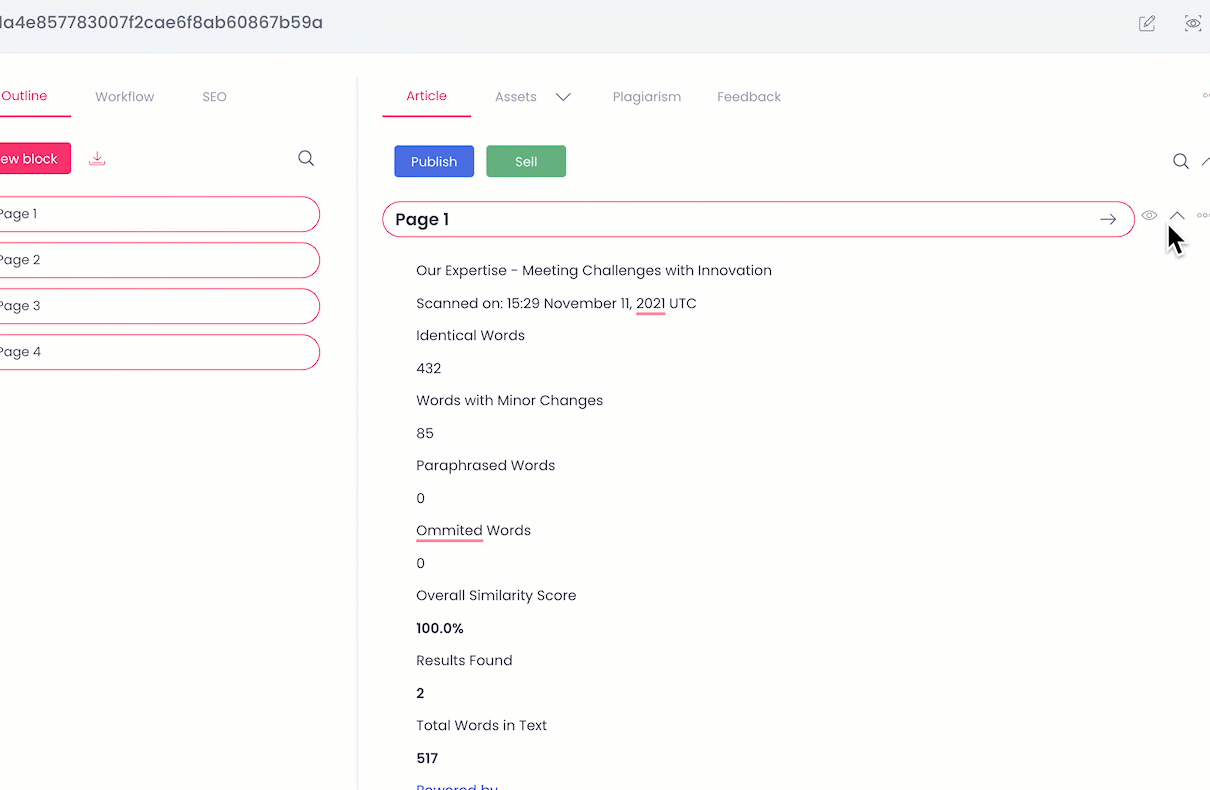
Extract PDF into an existing article:
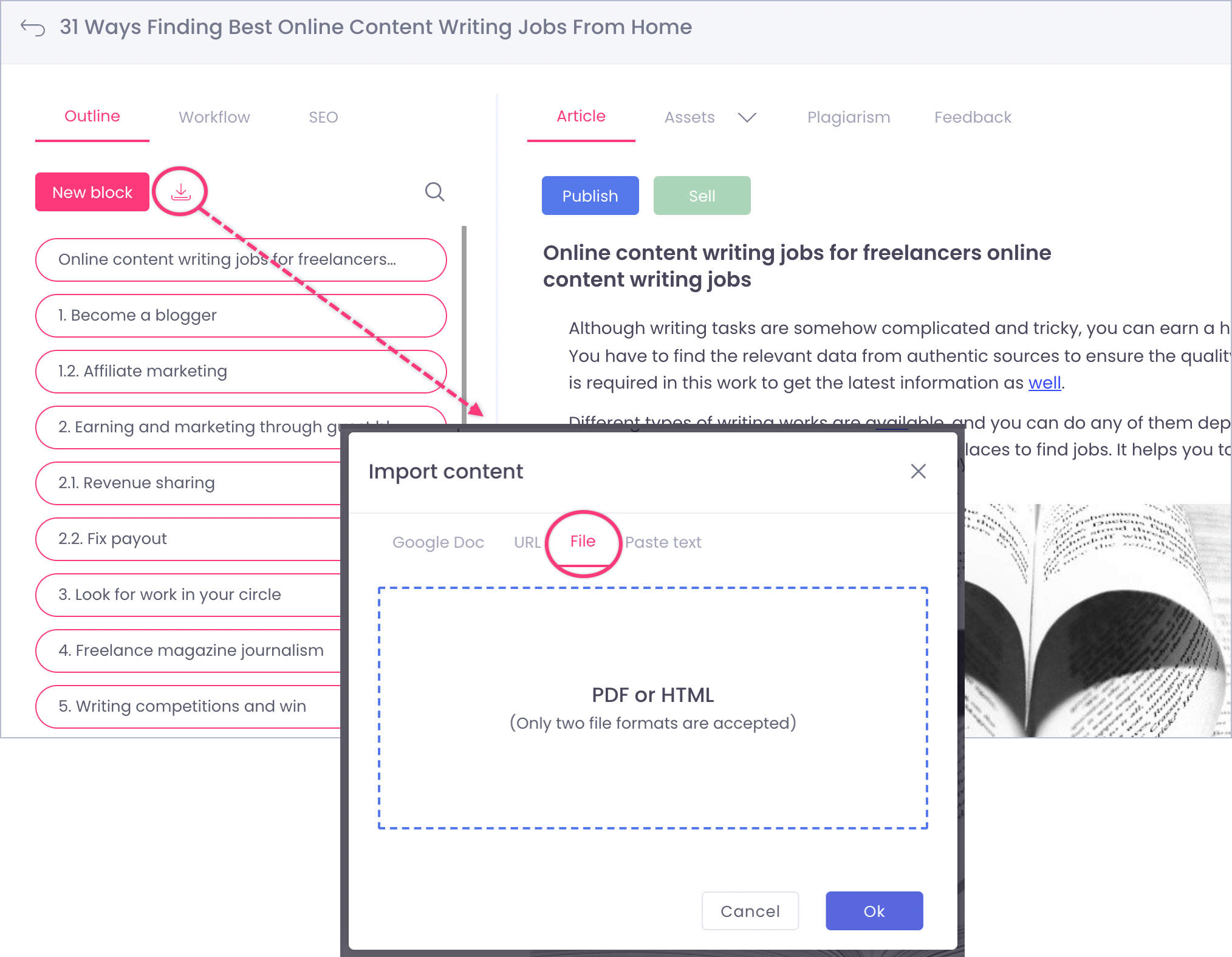
Imported data (text and images) is added to an existing article and divided into blocks. Each block = 1 page PDF.
Extract PDF into an existing Research Doc:
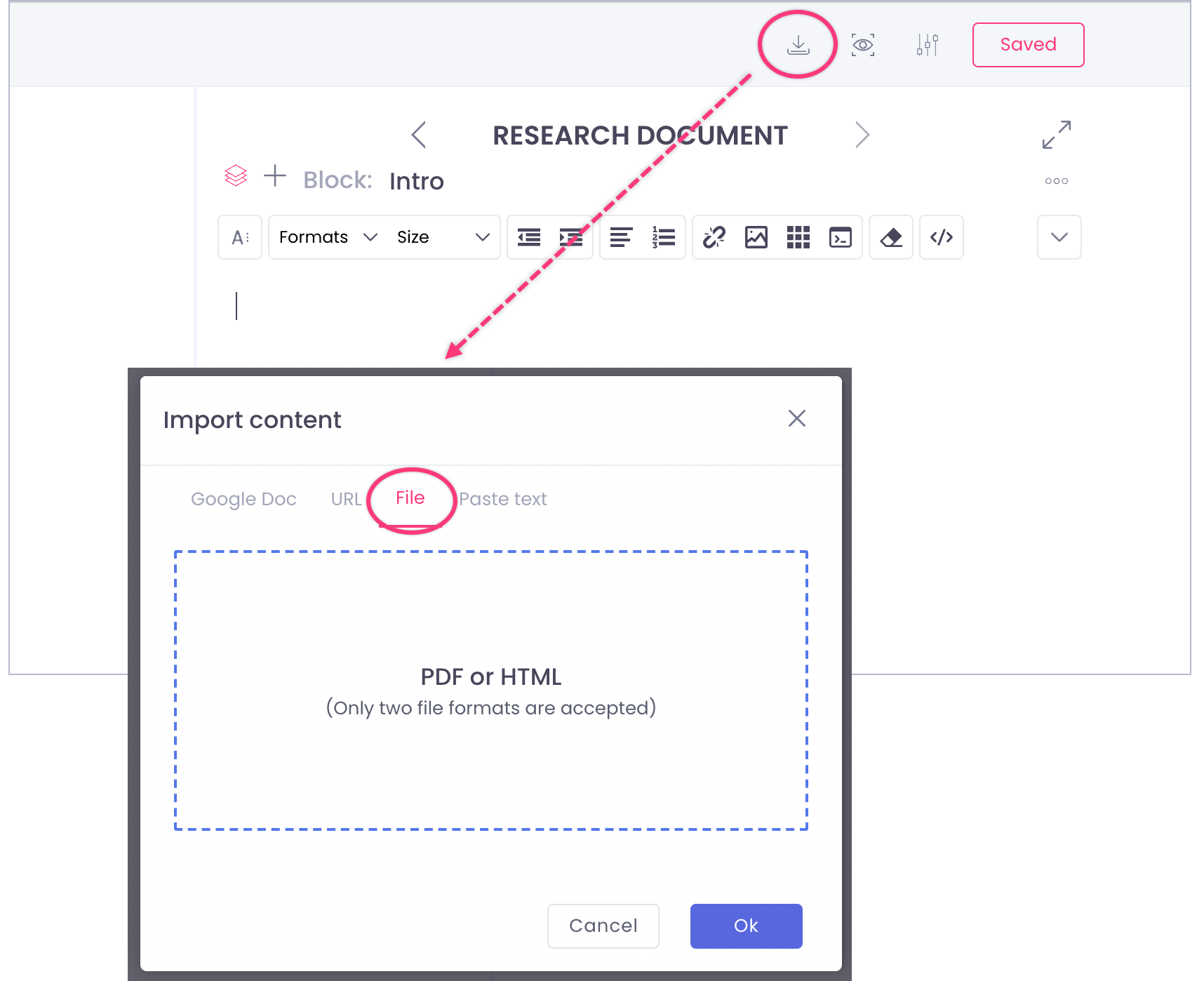
Same as in the article imported data (text and images) is added to an existing article and divided into blocks. Each block = 1 page PDF.
4